Wolfram Alpha just may take us one step closer to the elusive Semantic Web, by evolving a communication protocol out of its query terms.
(this is very much in ruminating form – comments welcome)
Wolfram Alpha officially launched on May 18, an exciting new kind of "computational" search engine which, rather than looking up documents where your questions have been answered before, actually computes the answer. The difference, as Stephen Wolfram himself has said, is that if you ask what the distance is to the moon, Google and other search engines will find you documents that tells you the average distance, whereas Wolfram Alpha will calculate what the distance is right now, and tell you that, in addition to many other facts (such as the average). Wolfram Alpha does not store answers, but creates them every time. And it does primarily answer numerical, computable questions.
The difference between Google (and other search engines) and Wolfram Alpha is not so clear-cut, of course. If you ask Google "17 mpg in liters per 100km" it will calculate the result for you. And you can send Wolfram Alpha non-computational queries such as "Norway" and it will give an informational answer. The difference lies more in what kind of data the two services work against, and how they determine what to show you: Google crawls the web, tracking links and monitoring user responses, in a sense asking every page and every user of their services what they think about all web pages (mostly, of course, we don’t think anything about most of them, but in principle we do.) Wolfram Alpha works against a database of facts with a set of defined computational algorithms – it stores less and derives more. (That being said, they will both answer the question "what is the answer to life, the universe and everything" the same way….)
While the technical differences are important and interesting, the real difference between WA and Google lies in what kind of questions they can answer – to use Clayton Christensen’s concept, the different jobs you would hire them to do. You would hire Google to figuring out information, introduction, background and concepts – or to find that email you didn’t bother filing away in the correct folder. You would hire Alpha to answer precise questions and get the facts, rather than what the web collectively has decided is the facts.
The meaning of it all
Now – what will the long-term impact of Alpha be? Google has made us replace categorization with search – we no longer bother filing things away and remembering them, for we can find them with a few half-remembered keywords, relying on sophisticated query front-end processing and the fact that most of our not that great minds think depressingly alike. Wolfram Alpha, on the other hand, is quite a different animal. Back in the 80s, I once saw someone exhort their not very digital readers to think of the personal computer as a "friendly assistant who is quite stupid in everything but mathematics." Wolfram Alpha is quite a bit smarter than that, of course, but the fact is that we now have access to this service which, quite simply, will do the math and look up the facts for us. Our own personal Hermione Granger, as it is.
I think the long-term impact of Wolfram Alpha will be to further something that may not have started with Google, but certainly became apparent with them: The use of search terms (or, if you will, seeds) as references. It is already common to, rather than writing out a URL, to help people find something by saying "Google this and you will find it". I have a couple of blogs and a web page, but googling my name will get you there faster (and you can misspell my last name and still not miss.) The risk in doing that, of course, is that something can intervene. As I read (in this paper) General Motors, a few years ago, had an ad for a new Pontiac model, at the end of which they exhorted the audience to "Google Pontiac" to find out more. Mazda quickly set up a web page with Pontiac in it, bought some keywords on Google, and quite literally Shanghaied GM’s ad.
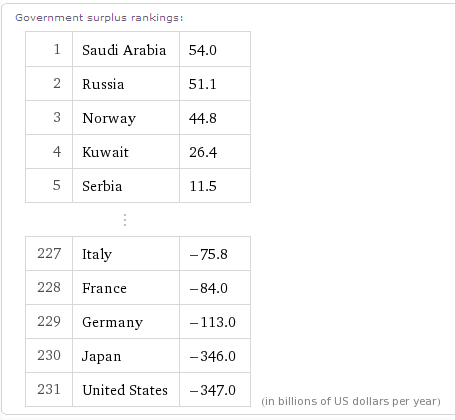
Wolfram Alpha, on the other hand, will, given the same input, return the same answer every time. If the answer should change, it is because the underlying data has changed (or, extremely rarely, because somebody figured out a new way of calculating it.) It would not be because someone external to the company has figured out a way to game the system. This means that we can use references to Wolfram Alpha as shorthand – enter "budget surplus" in Wolfram Alpha, and the results will stare you in the face. In the sense that math is a language for expressing certain concepts in a very terse and precise language, Wolfram Alpha seeds will, I think, emerge as a notation for referring to factual information.
A short detour into graffiti
Back in the early-to-mid-90s, Apple launched one of the first pen-based PDAs, the Apple Newton. The Newton was, for its time, an amazing technology, but for once Apple screwed it up, largely because they tried to make the device do too much. One important issue was the handwriting recognition software – it would let you write in your own handwriting, and then try to interpret it. I am a physician’s son, and I certainly took after my father in the handwriting department. Newton could not make sense of my scribbles, even if I tried to behave, and, given that handwriting recognition is hard, it took a long time doing it. I bought one, and then sent it back. Then the Palm Pilot came, and became the device to get.
The Palm Pilot did not recognize handwriting – it demanded that you, the user, wrote to it in a sign language called Graffiti, which recognized individual characters. Most of the characters resembled the regular characters enough that you could guess what they were, for the others you either had to consult a small plastic card or experiment. The feedback was rapid, to experimenting usually worked well, and pretty soon you had learned – or, rather, your hand had learned – to enter the Graffiti characters rapidly and accurately.
Wolfram Alpha works in the same way as Graffiti did: As Steven Wolfram says in his talk at the Berkman Center, people start out writing natural language but pretty quickly trim it down to just the key concepts (a process known in search technology circles as "anti-phrasing".) In other words, by dint of patience and experimentation, we (or, at least, some of us) will learn to write queries in a notation that Wolfram Alpha understands, much like our hands learned Graffiti.
From links to seeds to semantics
Semantics is really about symbols and shorthand – a word is created as shorthand for a more complicated concept by a process of internalization. When learning a language, rapid feedback helps (which is why I th
ink it is easier to learn a language with a strict and terse grammar rather than a permissive one), simplicity helps, and a structure and culture that allows for creating new words by relying on shared context and intuitive combinations (see this great video with Stephen Fry and Jonathan Ross on language creation for some great examples.)
And this is what we need to do – gather around Wolfram Alpha and figure out the best way of interacting with the system -and then conduct "what if" analysis of what happens if we change the input just a little. To a certain extent, it is happening already, starting with people finding Easter Eggs – little jokes developers leave in programs for users to find. Pretty soon we will start figuring out the notation, and you will see web pages use Wolfram Alpha queries first as references, then as modules, then as dynamic elements.
It is sort of quirky when humans start to exchange query seeds (or search terms, if you will). It gets downright interesting when computers start doing it. It would also be part of an ongoing evolution of gradually increasing meaningfulness of computer messaging.
When computers – or, if you will, programs – needed to exchange information in the early days, they did it in a machine-efficient manner – information was passed using shared memory addresses, hexadecimal codes, assembler instructions and other terse and efficient, but humanly unreadable encoding schemes. Sometime in the early 80s, computers were getting powerful enough that the exchanges gradually could be done in human-readable format – the SMTP protocol, for instance, a standard for exchanging email, could be read and even hand-built by humans (as I remember doing in 1985, to send email outside the company network I was on.) The world wide web, conceived in the early 90s and live to a wider audience in 1994, had at its core an addressing system – the URL – which could be used as a general way of conversing between computers, no matter what their operating system or languages. (To the technology purists out there – yes, WWW relies on a whole slew of other standards as well, but I am trying to make a point here) It was rather inefficient from a machine communication perspective, but very flexible and easy to understand for developers and users alike. Over time, it has been refined from pure exchange of information to the sophisticated exchanges needed to make sure it really is you when you log into your online bank – essentially by increasing the sophistication of the HTML markup language towards standards such as XML, where you can send over not just instructions and data but also definitions and metadata.
The much-discussed semantic web is the natural continuation of this evolution – programming further and further away from the metal, if you will. Human requests for information from each other are imprecise but rely on shared understanding of what is going on, ability to interpret results in context, and a willingness to use many clues and requests for clarification to arrive at a desired result. Observe two humans interacting over the telephone – they can have deep and rich discussions, but as soon as the conversation involves computers, they default to slow and simple communication protocols: Spelling words out (sometimes using the international phonetic alphabet), going back and forth about where to apply mouse clicks and keystrokes, double-checking to avoid mistakes. We just aren’t that good at communicating as computers – but can the computers eventually get good enough to communicate with us?
I think the solution lies in mutual adaptation, and the exchange of references to data and information in other terms than direct document addresses may just be the key to achieving that. Increases in performance and functionality of computers have always progressed in a punctuated equilibrium fashion, alternating between integrated and modular architectures. The first mainframes were integrated with simple terminal interfaces, which gave way to client-server architectures (exchanging SQL requests), which gave way to highly modular TCP/IP-based architectures (exchanging URLs), which may give way to mainframe-like semi-integrated data centers. I think those data centers will exchange information at a higher semantic level than any of the others – and Wolfram Alpha, with its terse but precise query structure may just be the way to get there.




 The interesting point here, of course, is how Goliath reacts when David substitutes effort for talent and rule-bending (or, rather, rule exploitation) for tradition: By declaring that this is an unacceptable way of playing. During the 1990s, under the truly eccentric coach
The interesting point here, of course, is how Goliath reacts when David substitutes effort for talent and rule-bending (or, rather, rule exploitation) for tradition: By declaring that this is an unacceptable way of playing. During the 1990s, under the truly eccentric coach  The enabling vision is not a new thing. I remember a video (or, rather film) from IBM from the mid-80s about End User Computing – a notion that the role of IT was to provide the tools for end users, and then they could build their own systems rather than wait for IT to build for them. (This, incidentally, was also the motivation behind COBOL in the 70s: The language was supposedly so intuitive that end users would be able to describe the processes they wanted automated directly into the computer, obviating the need for anyone in a white coat.) The movie showed an end user (for some reason a very short man in a suit) sitting in front of a
The enabling vision is not a new thing. I remember a video (or, rather film) from IBM from the mid-80s about End User Computing – a notion that the role of IT was to provide the tools for end users, and then they could build their own systems rather than wait for IT to build for them. (This, incidentally, was also the motivation behind COBOL in the 70s: The language was supposedly so intuitive that end users would be able to describe the processes they wanted automated directly into the computer, obviating the need for anyone in a white coat.) The movie showed an end user (for some reason a very short man in a suit) sitting in front of a 